Desarrollo del proyecto
Extracción de datos
Para este procedimiento, tenemos 2 formas. La primera forma es mediante el uso
del lenguaje Python, haciendo uso de las librerías [pandas, Seaborn] en el
entorno de Visual Studio Code, de la siguiente manera:
1. Uso de Python bajo el entorno de Jupyter
Usamos las credenciales del token para descarga de data.
{"username":"######","key":"####################"}
En un entorno de Google Colab para ejecución de código Python:

Con los codelines de [2] y [3] garantizamos que no haya un archivo igual ‘.kaggle’ en la carpeta raíz.
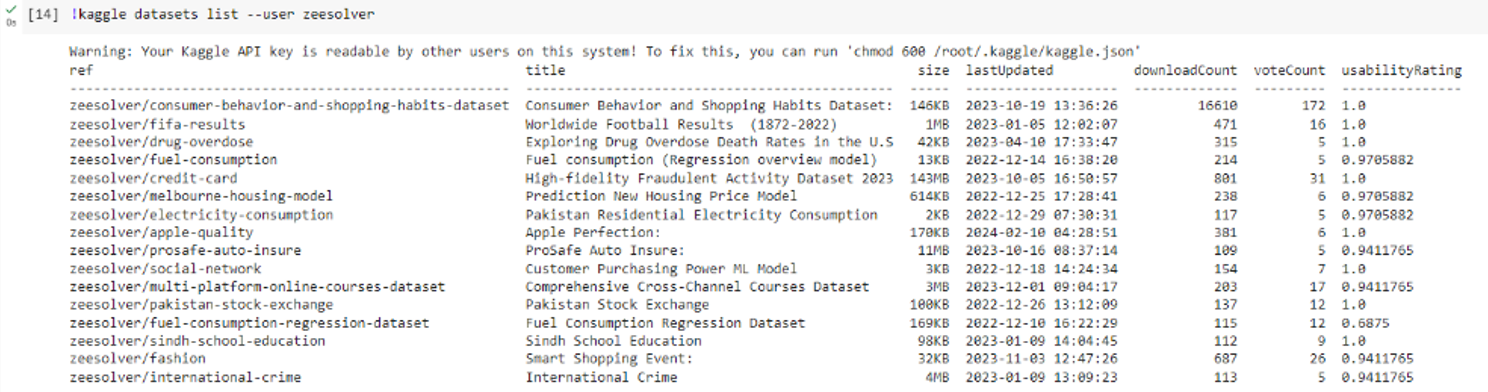
Con el codeline[14], podemos validar todos los dataset creados por el autor ‘zeesolver’. Procedemos a descargar el dataset de primera opción consumer-behavior-and-shopping-habits-dataset.csv.

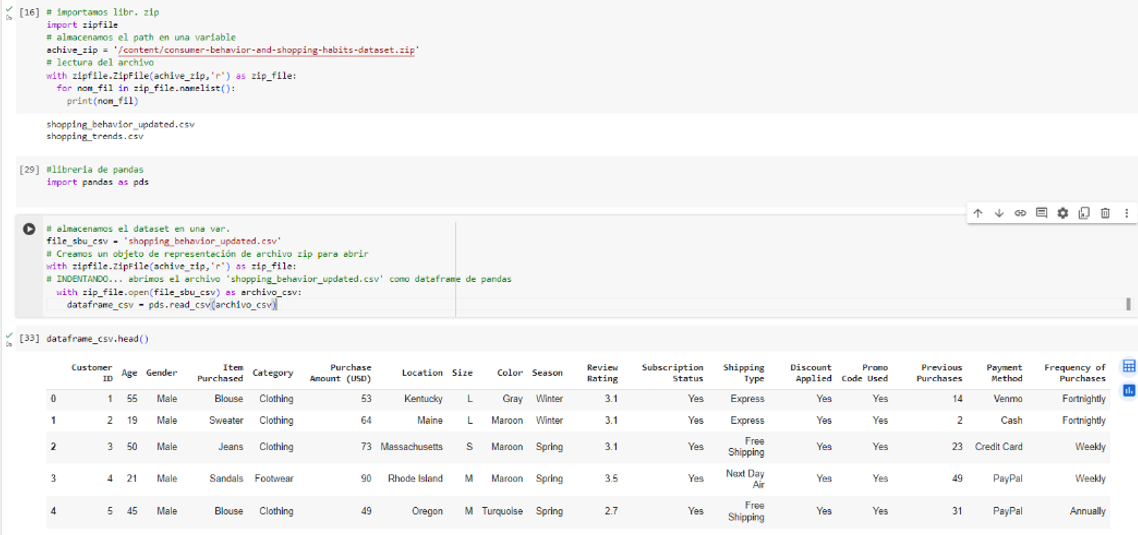
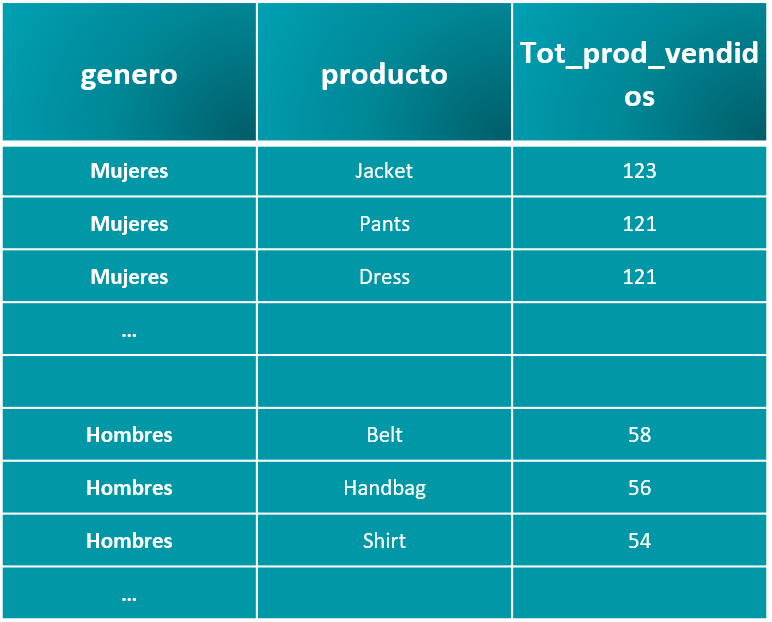
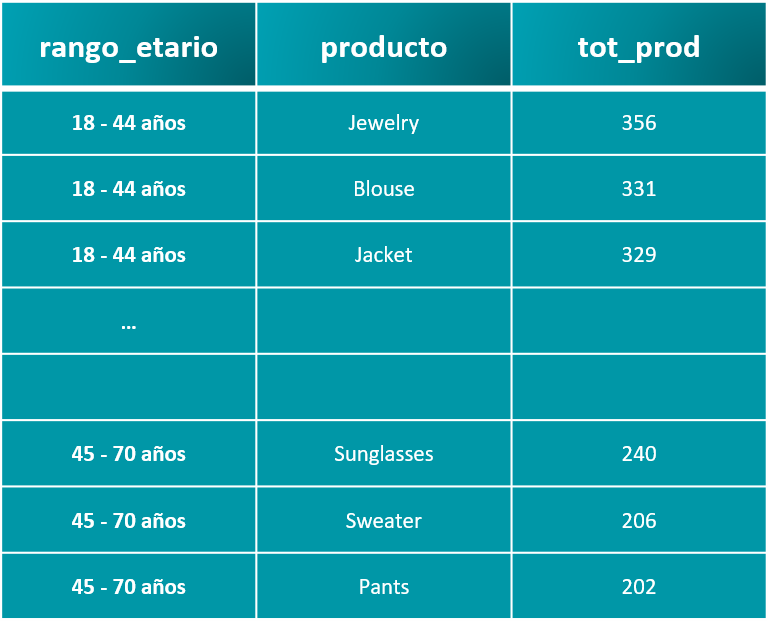
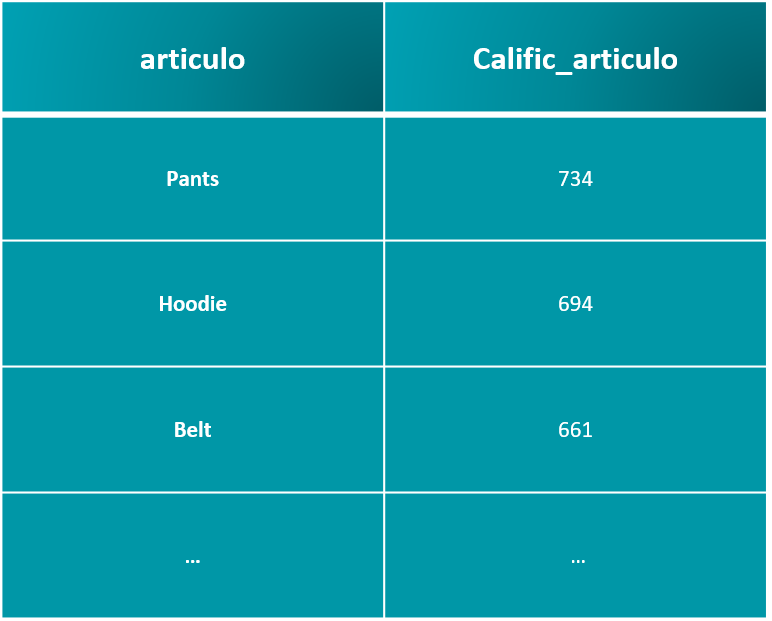
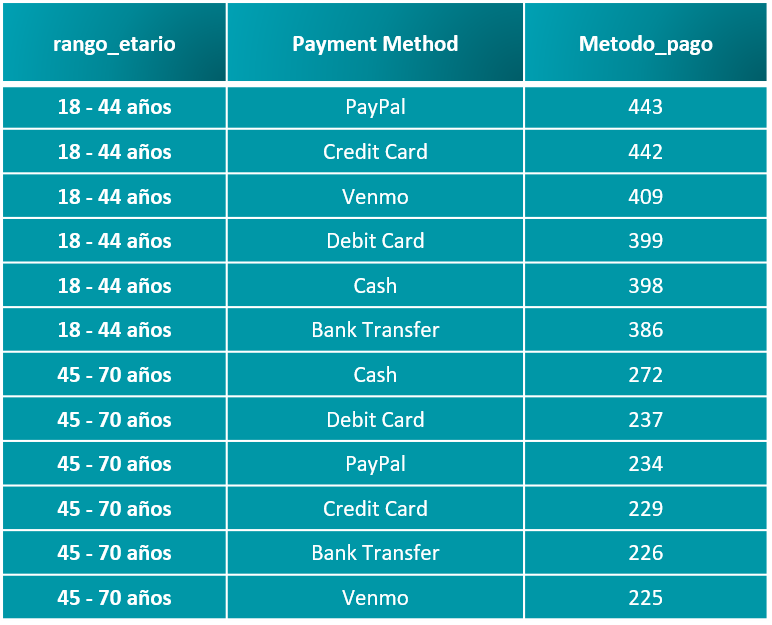
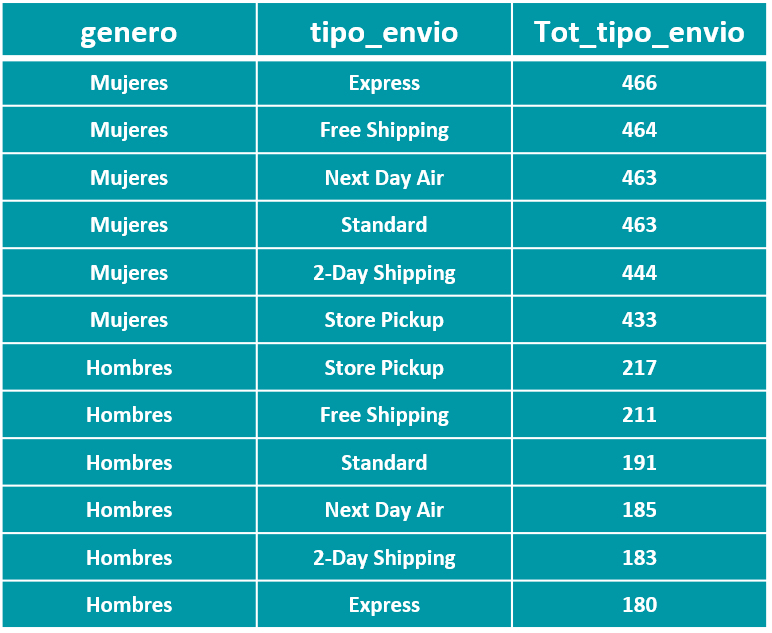
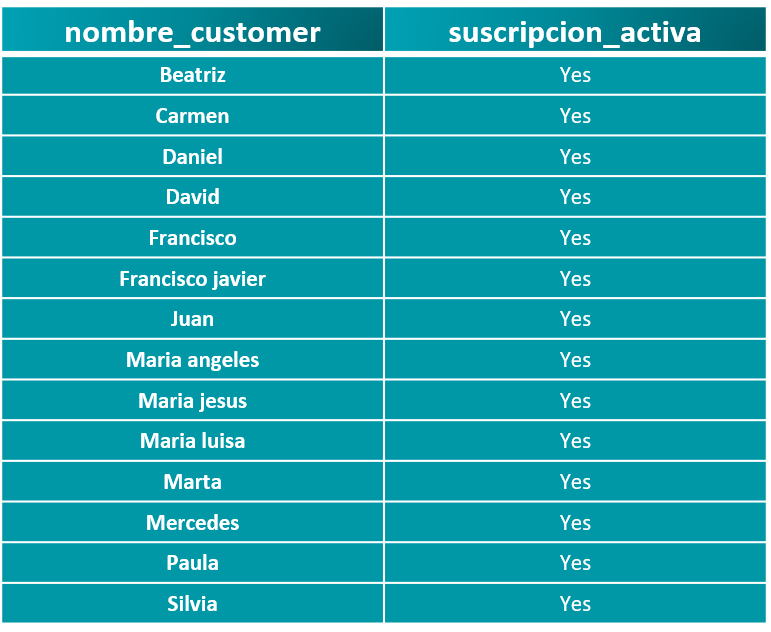
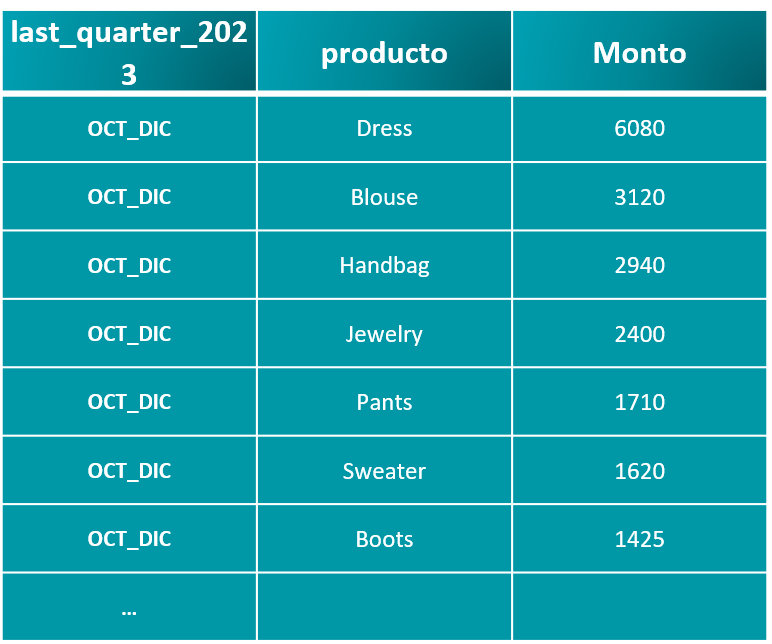
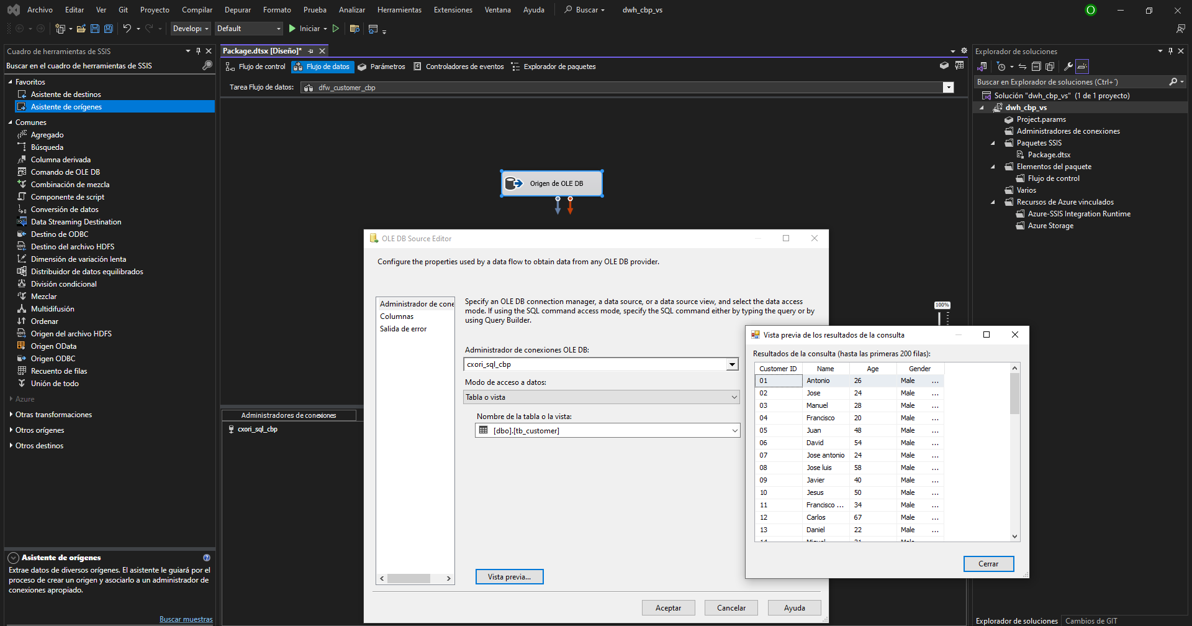
Podemos apreciar su tamaño y tipo de licenicia. Con los siguientes codelines procedemos a validar los primeros registros de la tabla “.head()”, así como su estructura, tipo de datos, posibles valores nulos, limpieza y transformación inmediata de ser necesario, entre otras funcionalidades.




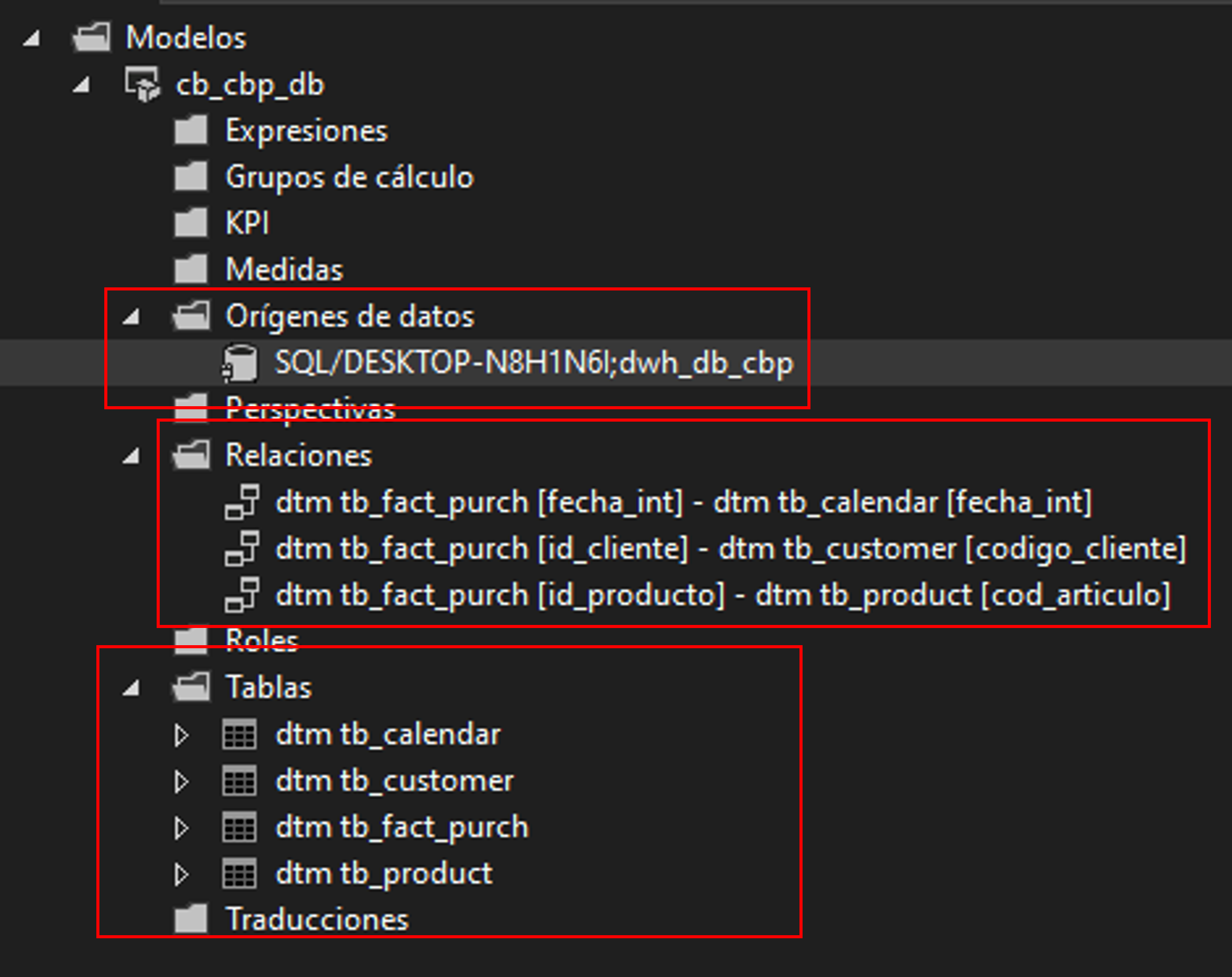

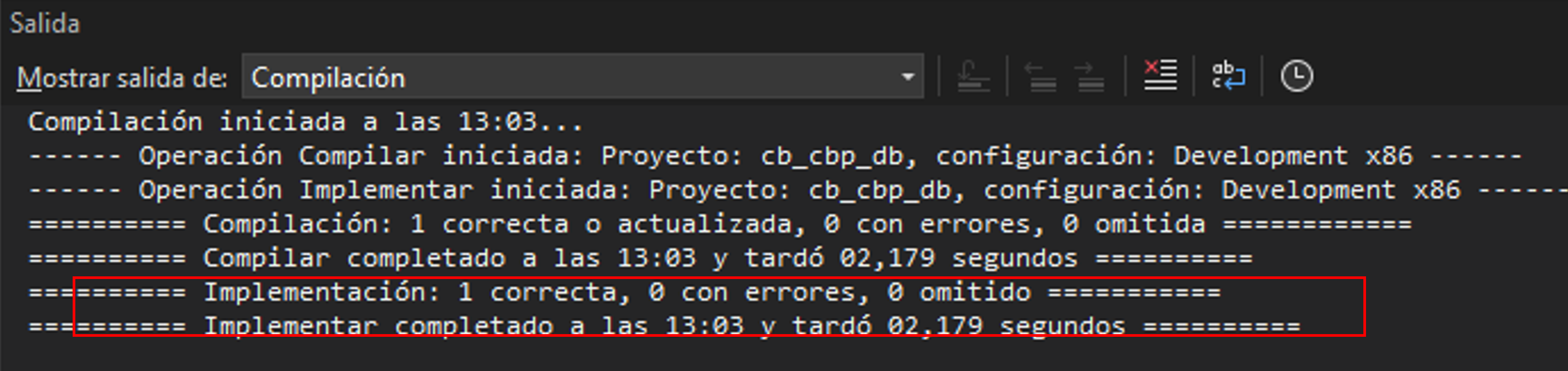
 :
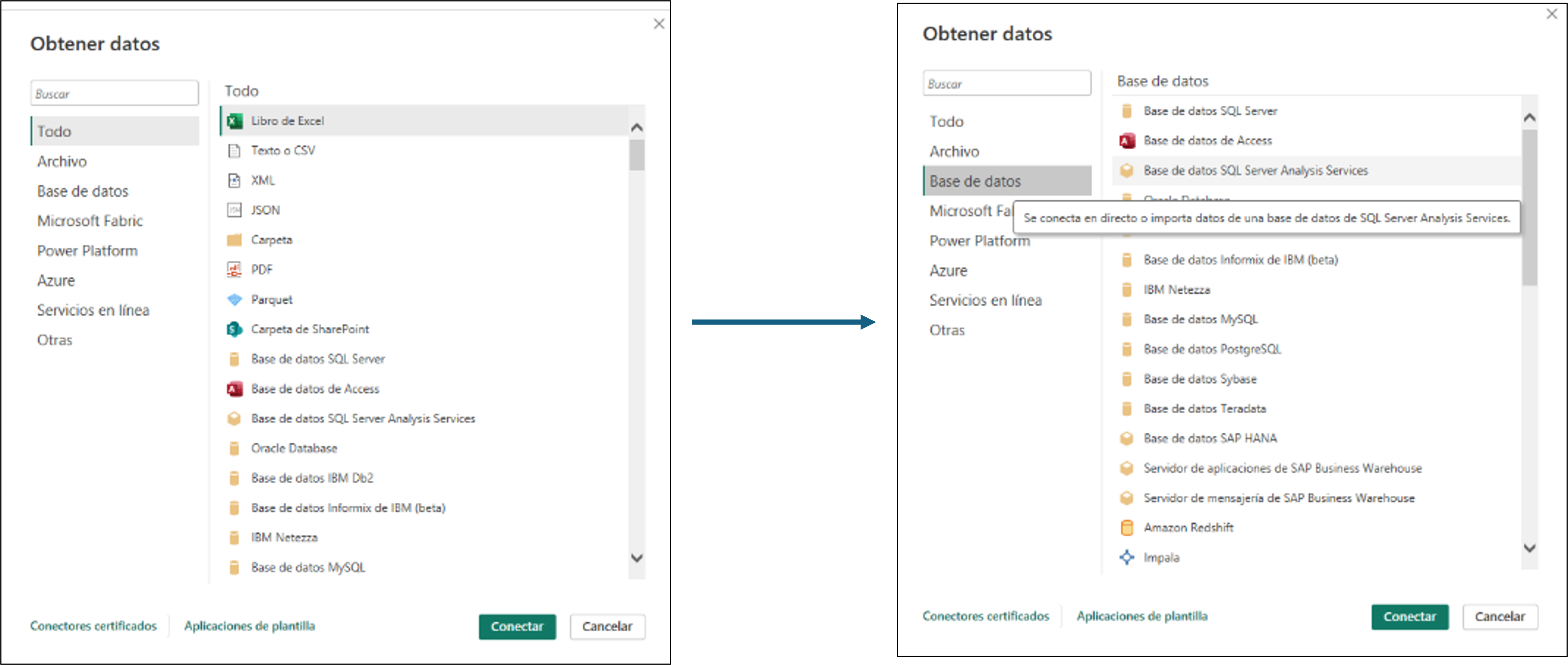
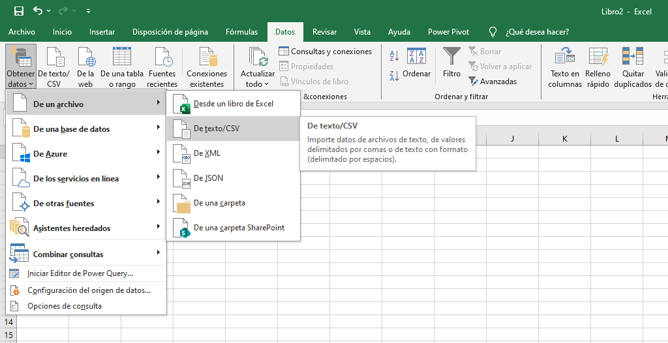
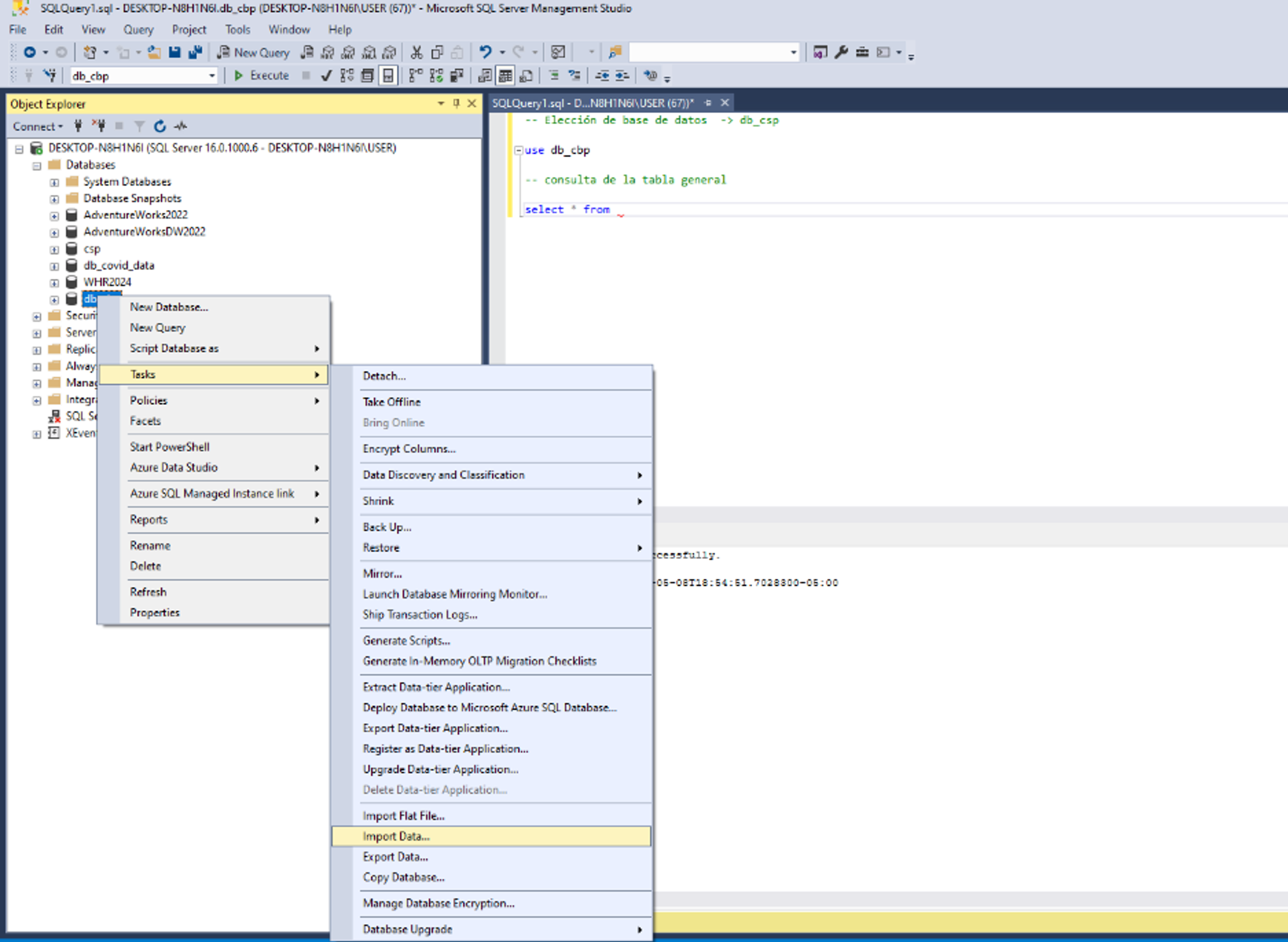
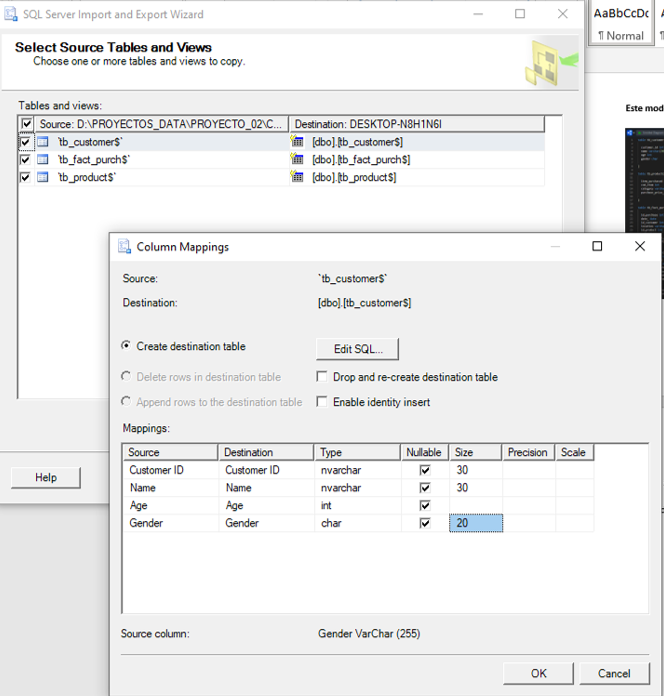
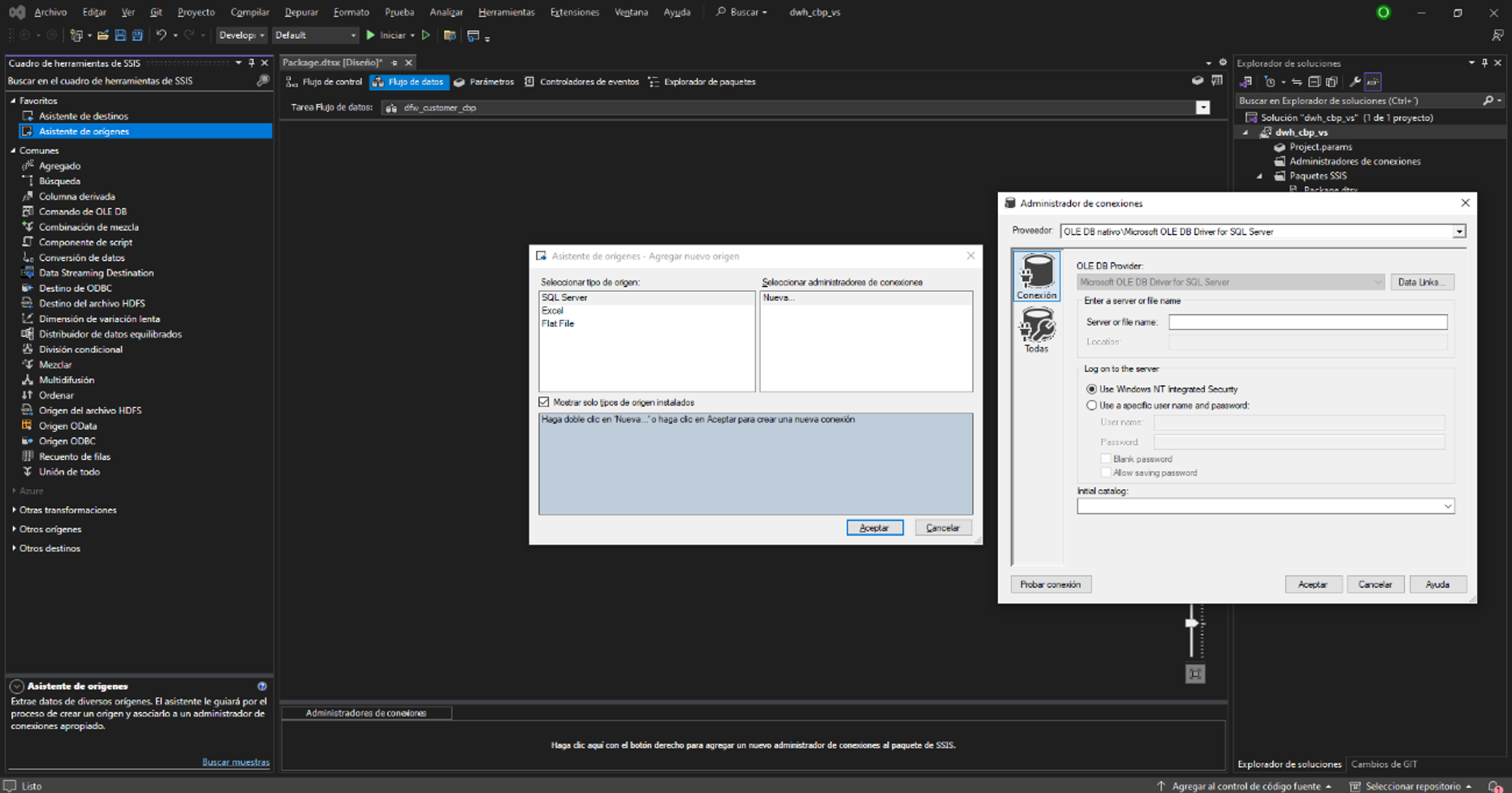
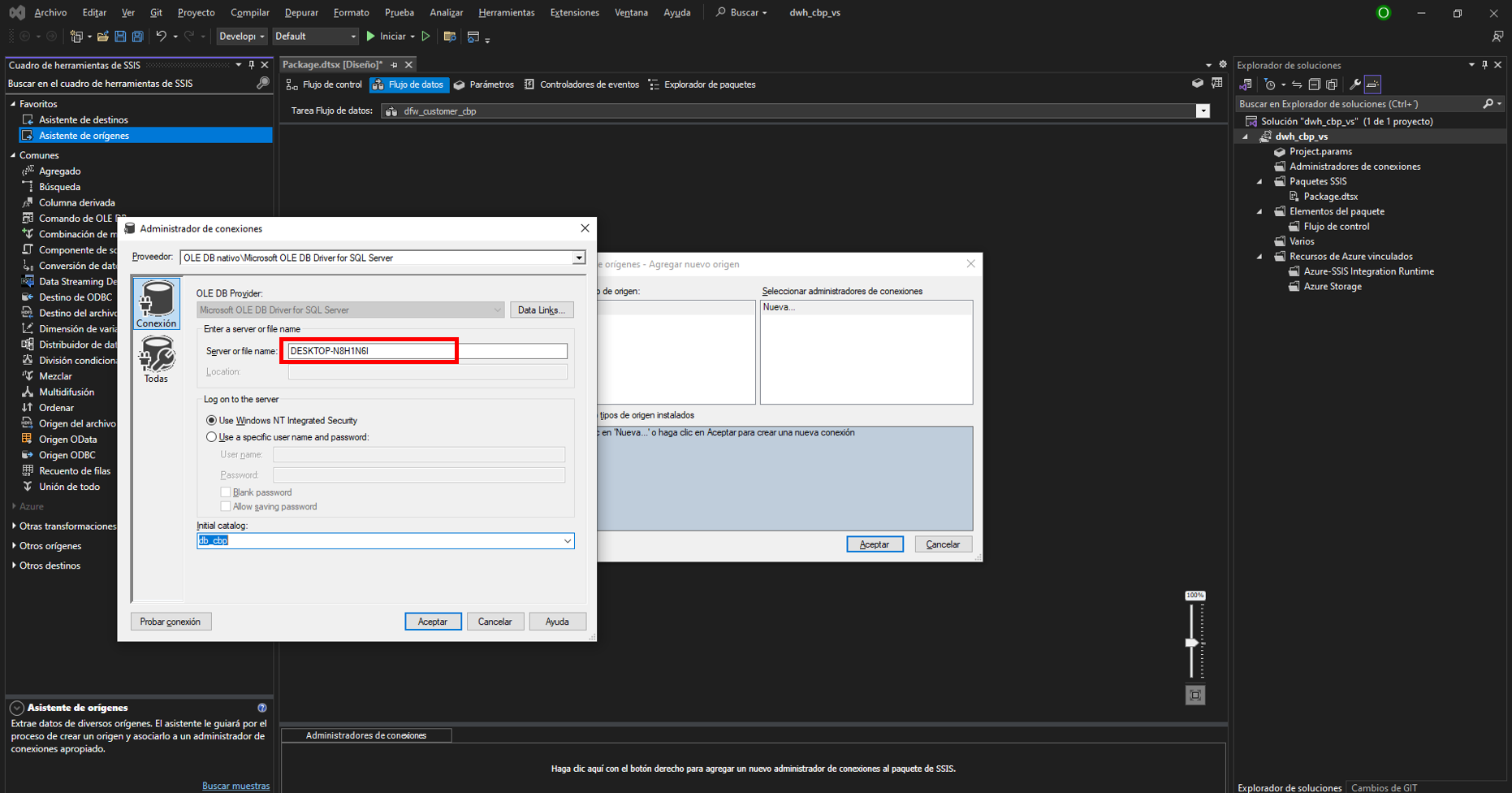
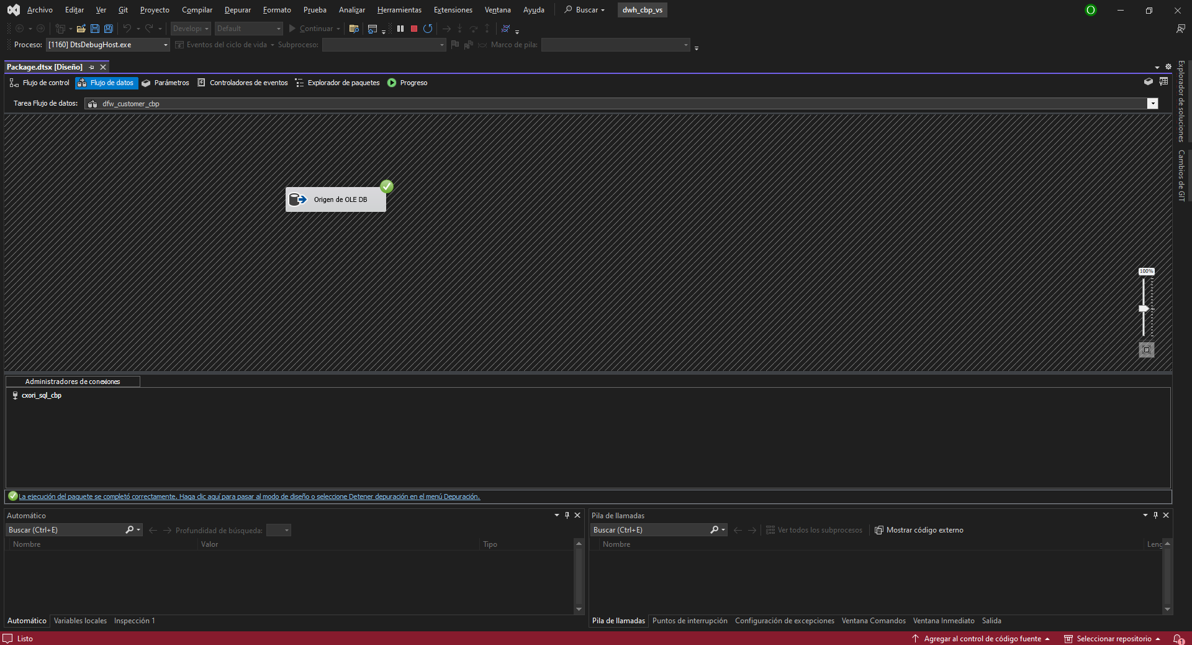
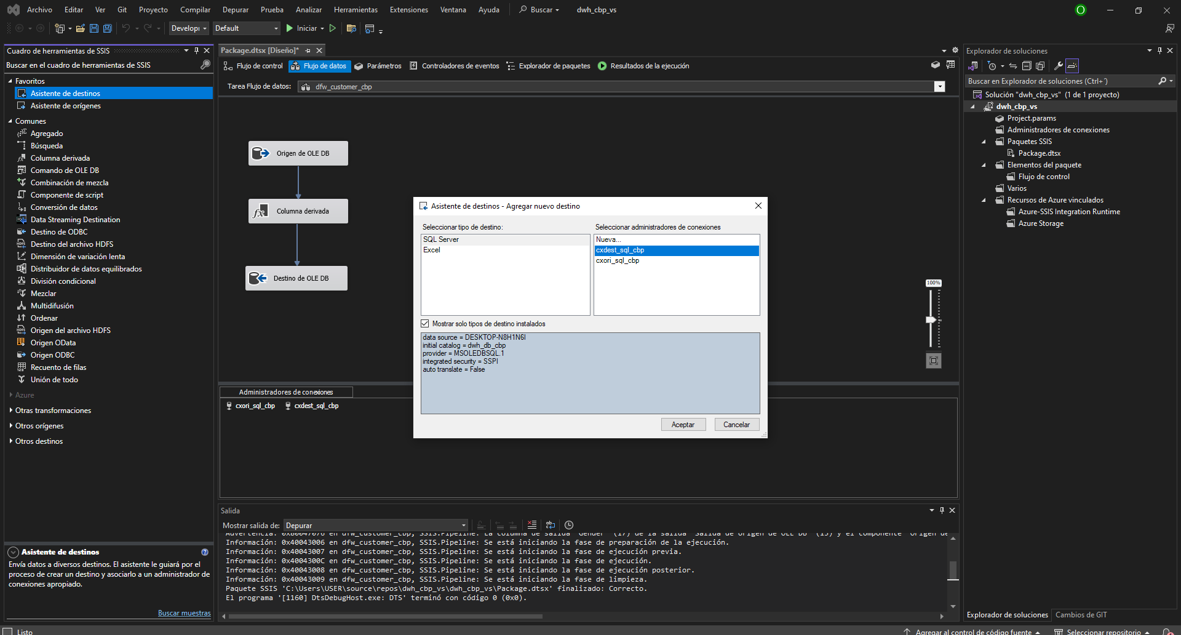
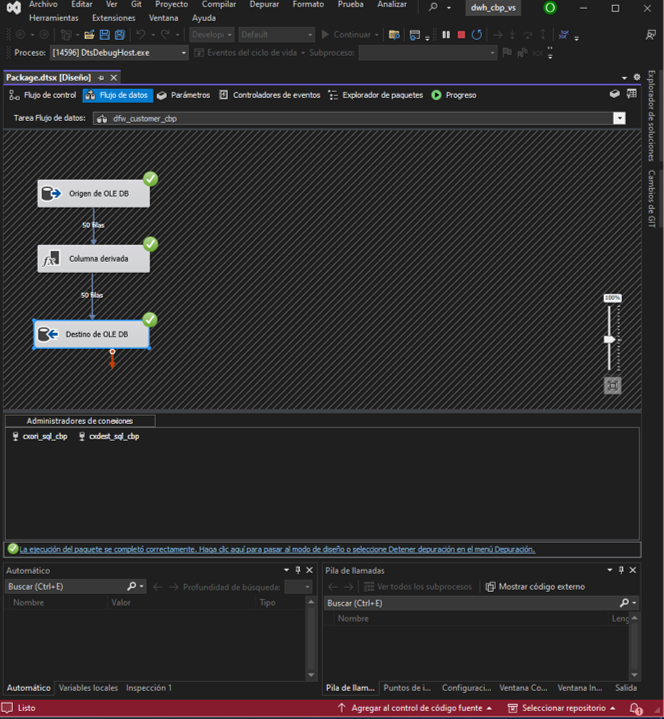
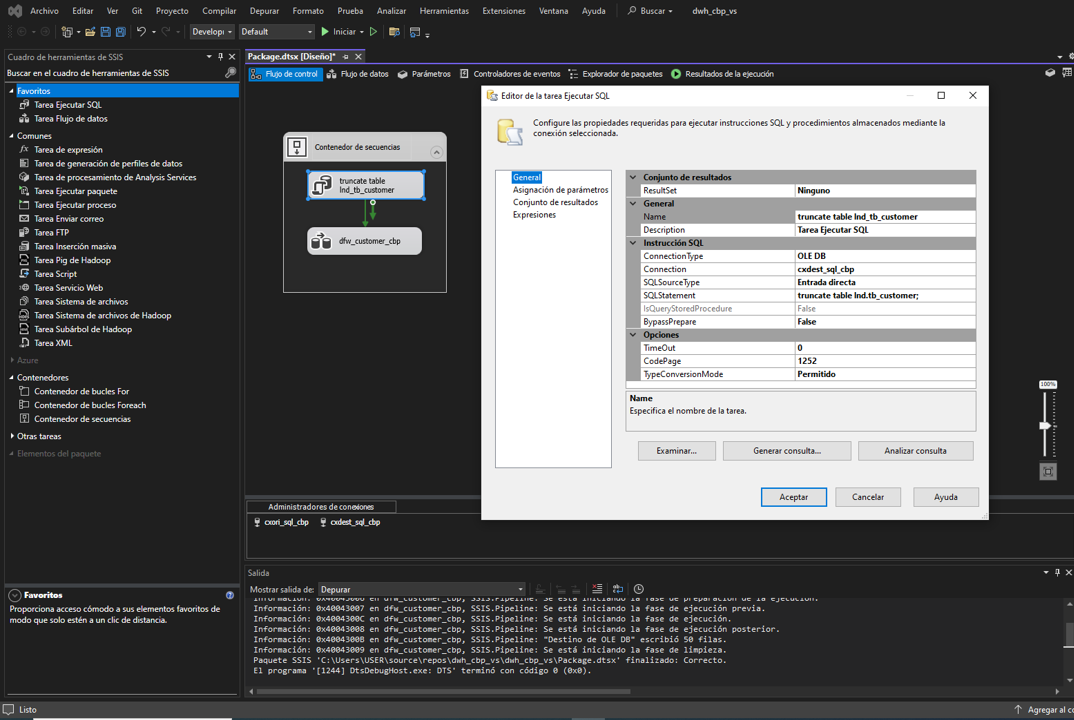
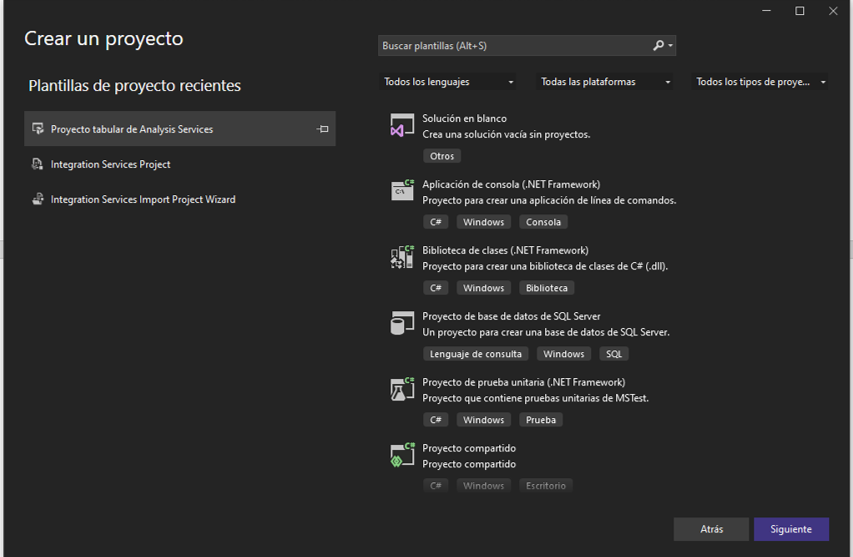
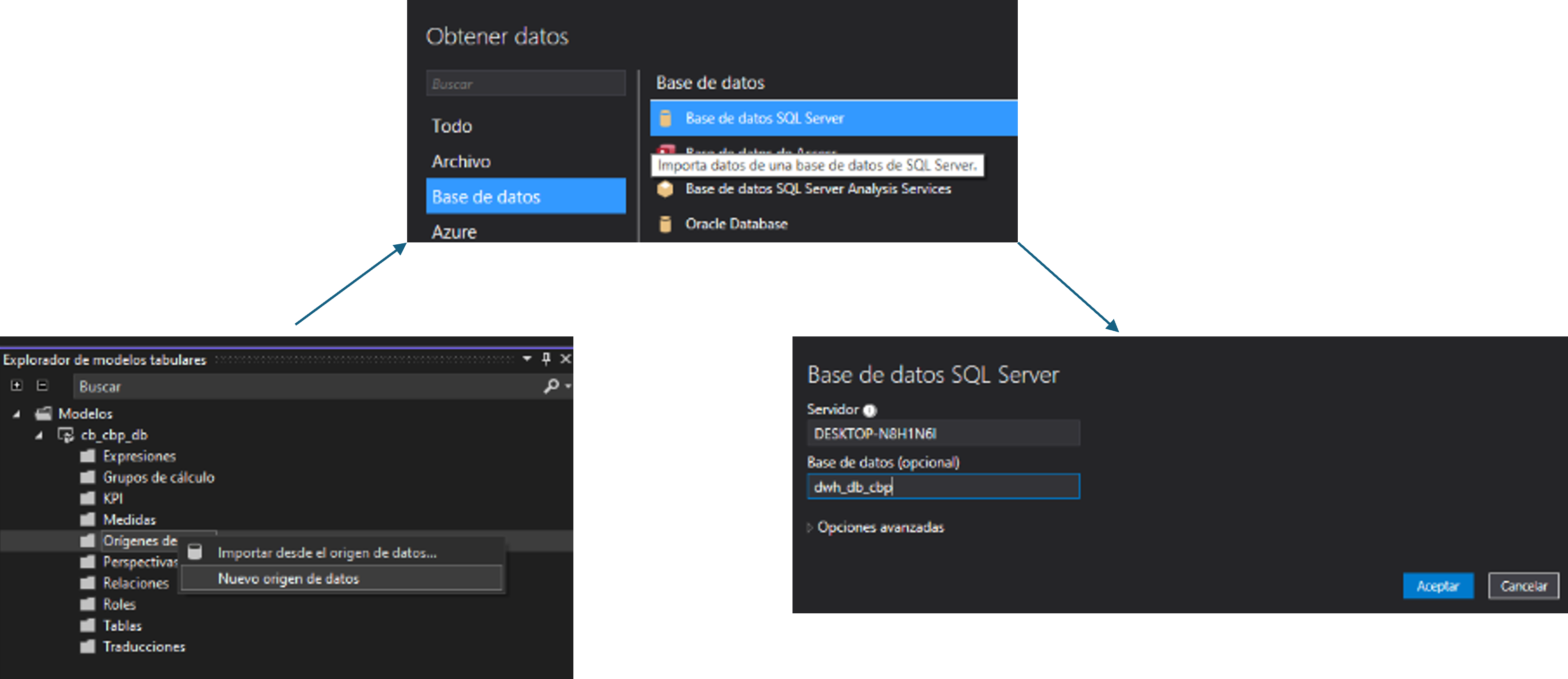
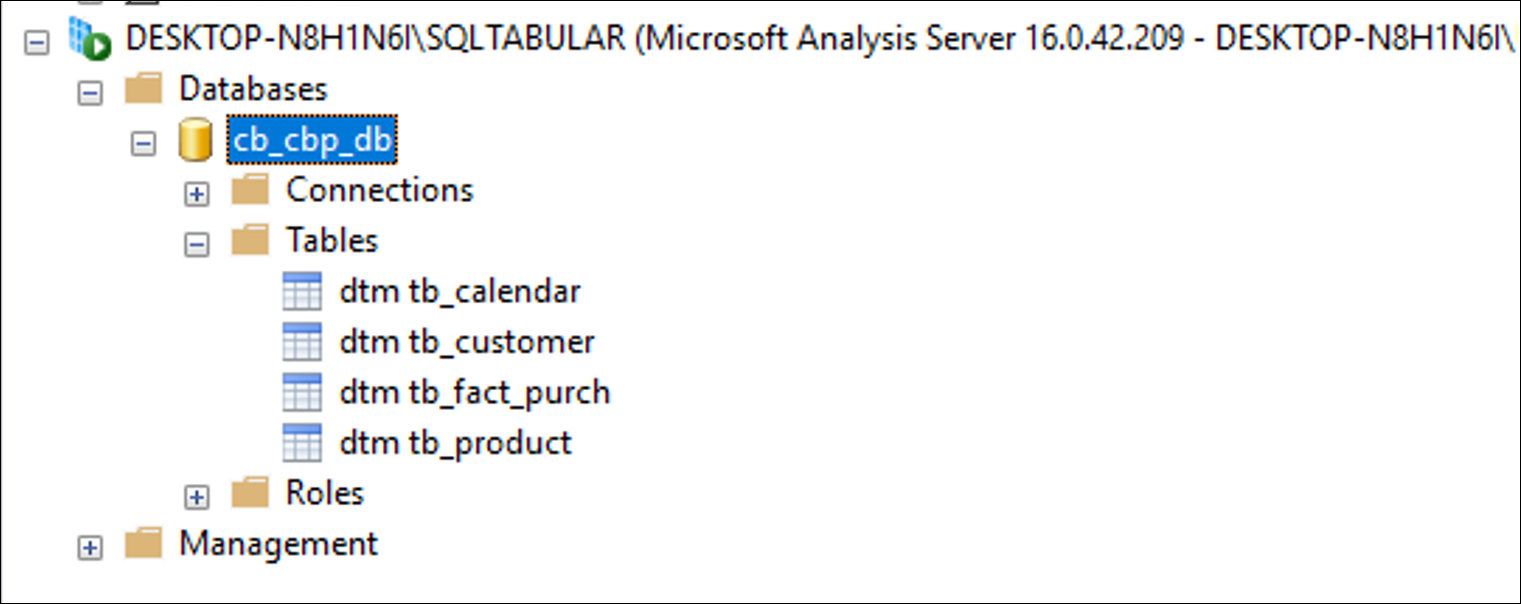
En el entorno, nos dirigimos a “obtener datos”, bases de datos y
Bases de datos SQL Server Analysis Services.
:
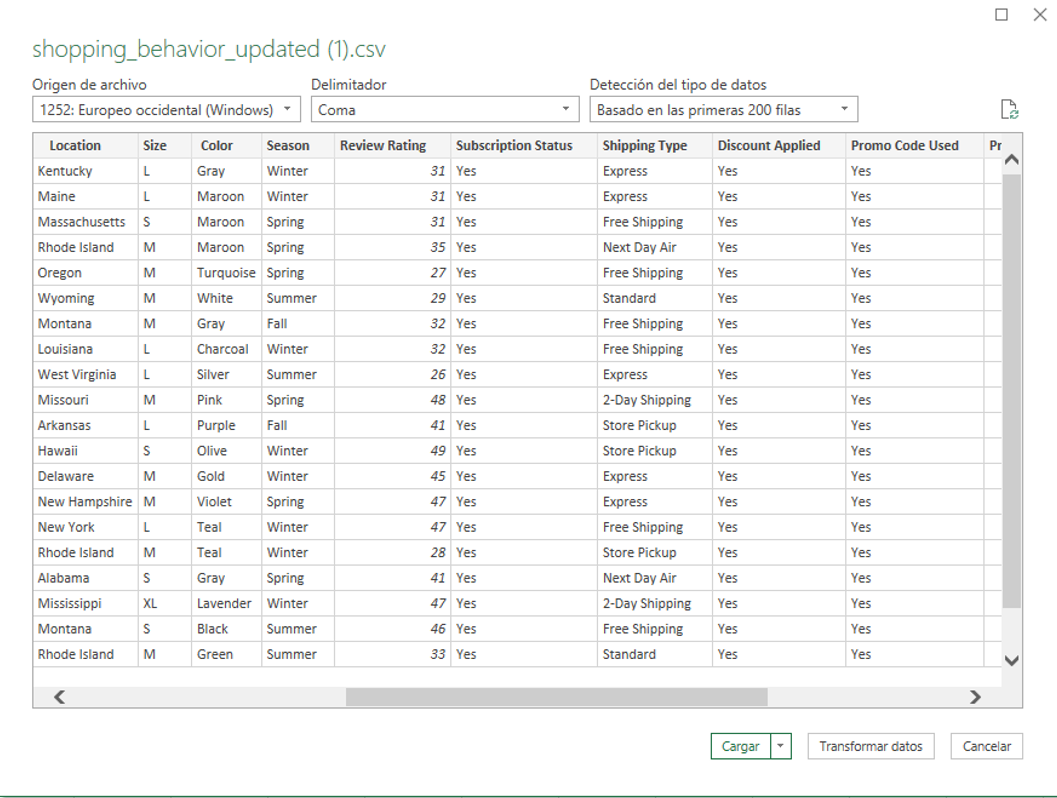
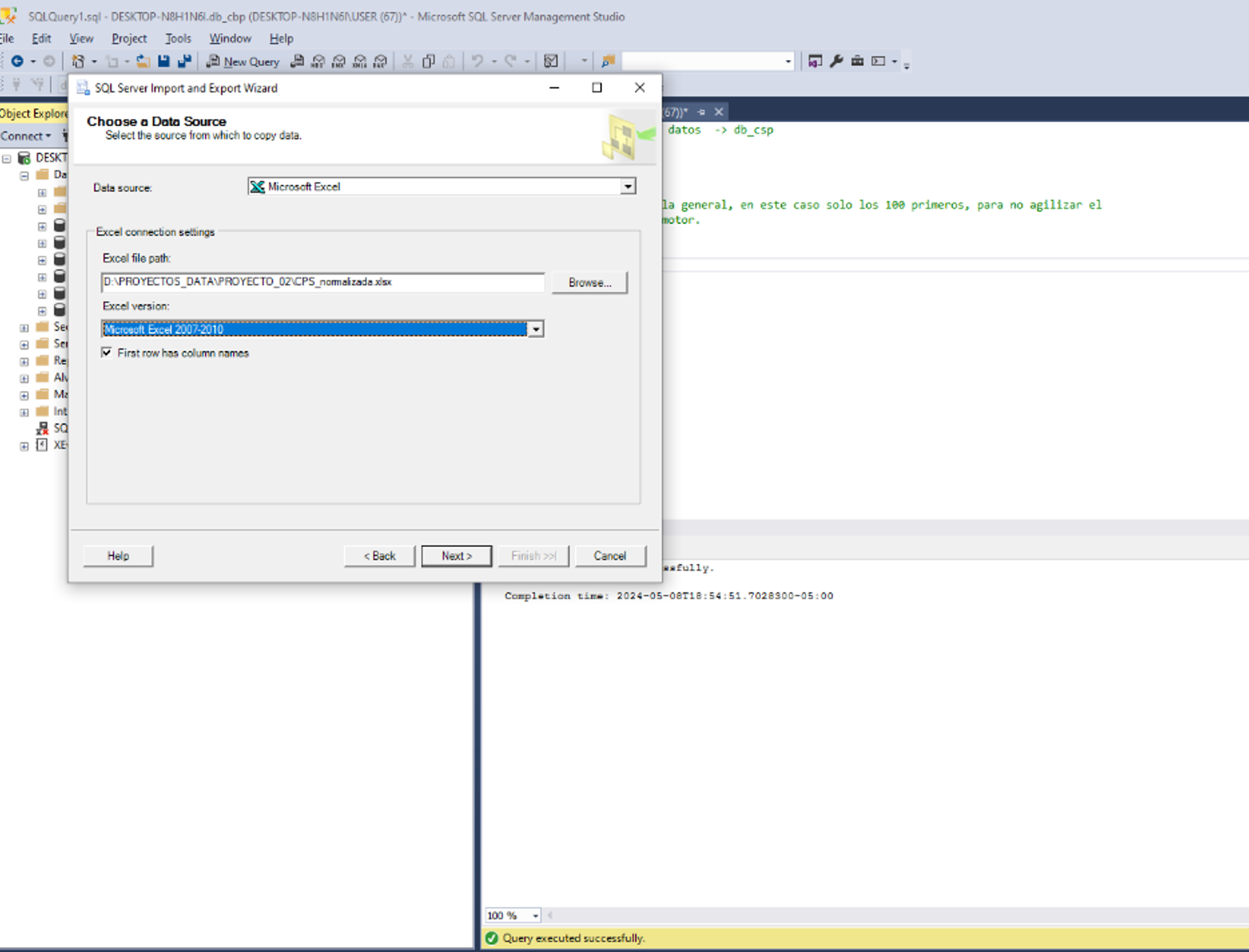
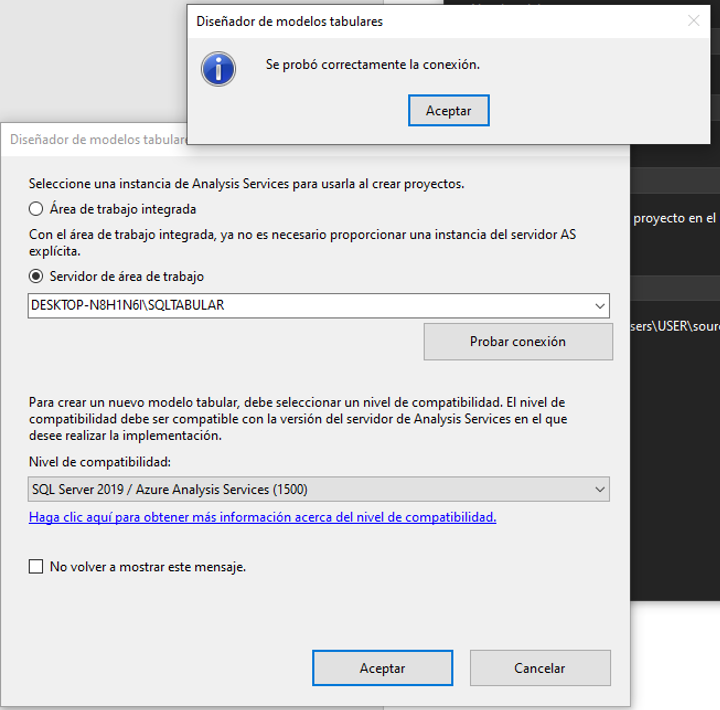
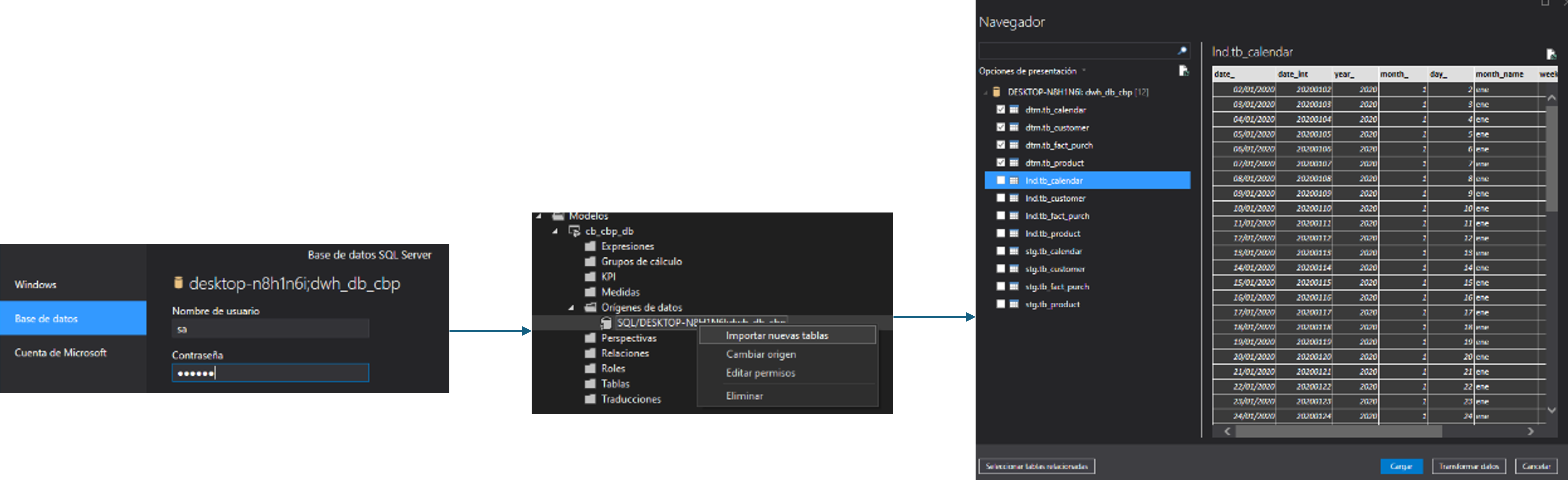
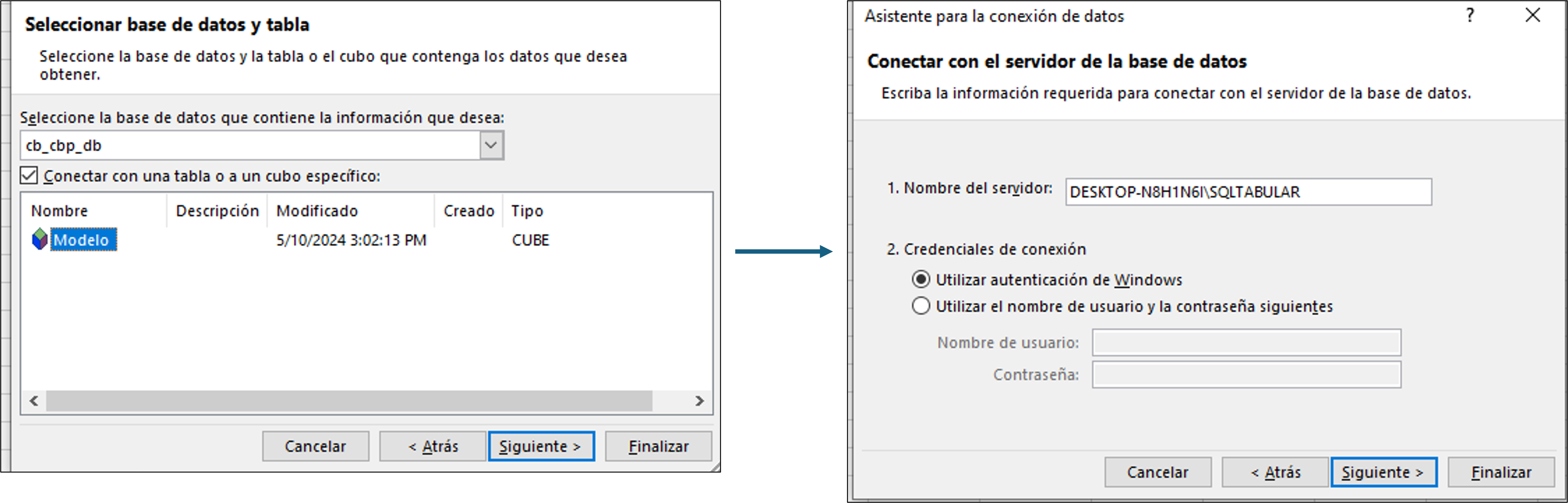
En el entorno, nos dirigimos a “obtener datos”, bases de datos y
Bases de datos SQL Server Analysis Services.